Data Mining ist der Prozess der Entdeckung von Mustern, Anomalien und nützlichen Informationen in großen Datensätzen mithilfe verschiedener Methoden und Techniken. Es handelt sich um einen wesentlichen Bestandteil der Datenanalyse, der in vielen Bereichen eingesetzt wird, um fundierte Entscheidungen zu treffen und mehr aus den vorhandenen Daten herauszuholen. Ziel ist es, aus riesigen Datenmengen sinnvolle Informationen zu extrahieren, die Unternehmen und Forscher nutzen können.
Unterarten und Begriffe von Big Data
Data Mining umfasst verschiedene Unterarten, die jedes eine spezifische Funktion innerhalb der Datenanalyse übernehmen und jeweils auf unterschiedliche Datensätze und Zwecke abgestimmt sind.
- Klassifikation: Die Klassifikation ist ein zentraler Aspekt im Data Mining und bezeichnet die Aufteilung eines Datensatzes in unterschiedliche Kategorien oder Klassen. Klassifizierungsmethoden nutzen bestehende Daten, um modellbasierte Annahmen zu treffen und zukünftige Dateneinträge zu klassifizieren.
- Clustering: Clustering bezieht sich auf die Gruppierung von Datenpunkten, die in irgendeiner Weise ähnlich sind. Anders als bei der Klassifikation, werden beim Clustering keine vordefinierten Labels verwendet. Stattdessen basieren die Gruppenentzündungen rein auf naturalischen Datenmuster.
- Regression: Regression wird verwendet, um die Beziehungen zwischen Datenelementen zu quantifizieren und vorherzusagen. Diese Technik wird häufig verwendet, um zukünftige Trends zu prognostizieren und zu verstehen, wie Variablen voneinander abhängen.
- Assoziationsregel-Lernen: Diese Unterart des Data Mining konzentriert sich auf die Entdeckung von Regeln, die Beziehungen und Abhängigkeiten in Datensätzen identifizieren. Ein prominentes Beispiel ist der Marktanalysesektor, wo Assoziationsregeln genutzt werden, um Kundenkäufe zu analysieren.
Wie wird Big Data im Internet angewandt?
Data Mining wird im Internet in unterschiedlichen Formen angewandt, wobei diese Anwendungen häufig versteckt oder für den Endnutzer nicht direkt sichtbar sind:
- Personalisierte Werbung: Analyse von Nutzerdaten zur Gestaltung von gezielten Werbekampagnen.
- Empfehlungssysteme: Einsatz in Plattformen wie Amazon oder Netflix, um nutzeroptimierte Inhalte vorzuschlagen.
- Suchmaschinenoptimierung (SEO): urchsetzung fortschrittlicher Algorithmen zur Optimierung von Suchvorgängen.
- Soziale Netzwerke: Plattformen wie Facebook und Twitter nutzen Data Mining, um Trends zu erkennen, Nutzerinteraktionen zu analysieren und gezielte Inhalte anzuzeigen.
- Betrugserkennung: Identifizierung von Anomalien in Transaktionsdaten zur Betrugsprävention.
- Nutzerverhaltensanalyse: Ermittlung von Nutzungsmustern zur Verbesserung von Webseiten- oder App-Designs.
Wie funktioniert Data Mining?
Data Mining beruht auf einem ausgeklügelten Netzwerk von Mechaniken und Konzepten, die zusammenarbeiten, um aus Rohdaten bedeutungsvolle Einblicke zu gewinnen.
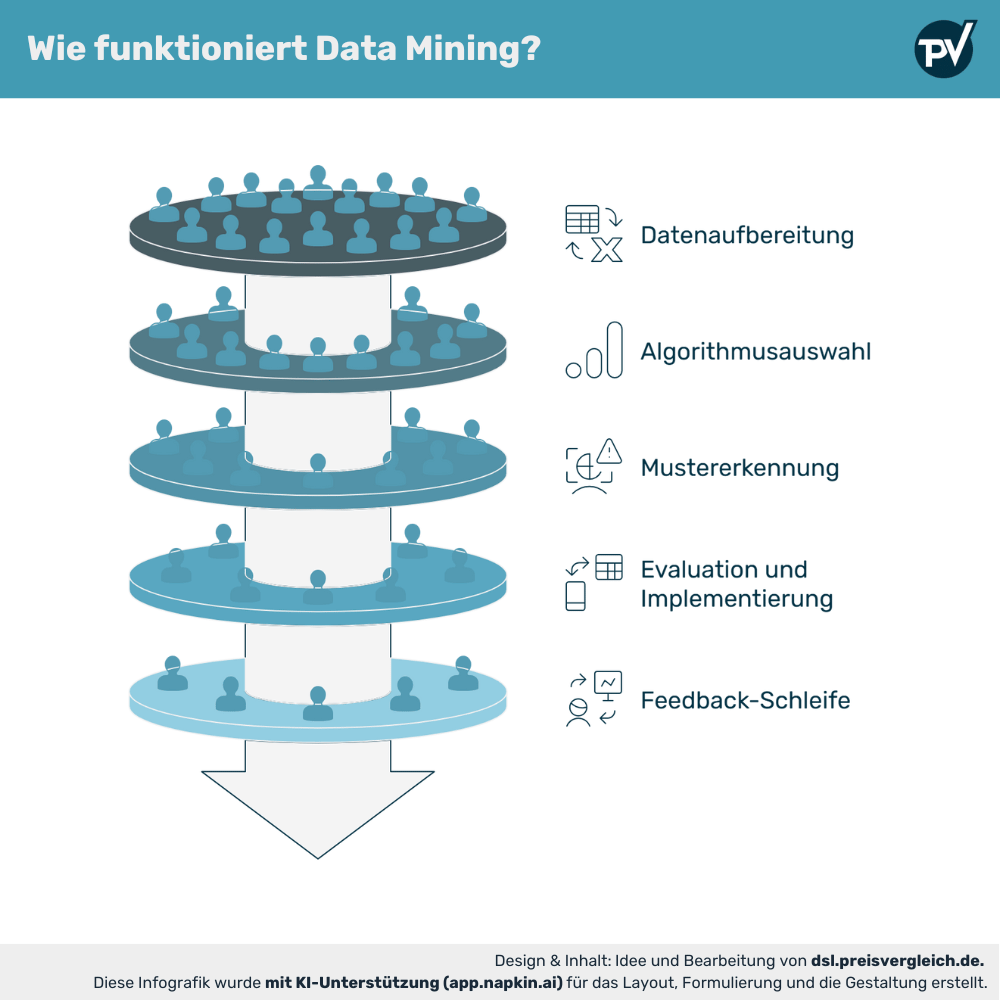
Datenaufbereitung
Bevor der eigentliche Mining-Prozess beginnt, müssen Daten gesammelt, bereinigt und in geeigneter Form vorpräpariert werden. Dies stellt sicher, dass die Subsequent Analysis auf soliden Grundlagen erfolgt.
Algorithmusauswahl
Die Wahl des richtigen Algorithmus ist entscheidend. Je nach Ziel und Datentyp können hier verschiedene Techniken wie Entscheidungsbäume, neuronale Netze oder k-Means-Clustering eingesetzt werden.
Mustererkennung
Hierbei werden die vorbereiteten Daten durch die Algorithmen analysiert, um Wiederkehrende Muster oder Anomalien zu identifizieren. Die Mustererkennung ist zudem der Grundstein für Vorhersagemodelle.
Evaluation und Implementierung
Abschließend werden die erkannten Muster auf ihre Sinnhaftigkeit evaluiert und, sofern sie nützlich sind, in Geschäftsentscheidungen oder andere Bereiche implementiert.
Feedback-Schleife
Ein oft übersehener, aber wichtiger Teil ist die Qualitätssicherung und Nachjustierung der angewendeten Modelle, um eine kontinuierliche Verbesserung zu gewährleisten.
Praktische Anwendungsbeispiele von Data Mining
Data Mining findet im Alltag vieler Branchen Anwendung und kann zu erstaunlichen funktionalen Vorteilen führen.
Kreditwürdigkeitseinschätzung
Im Finanzsektor nutzen Unternehmen Data Mining, um Kreditrisiken zu bewerten. Banken analysieren historische und aktuelle Daten der Kreditnehmer, um potenzielle Ausfallrisiken vorherzusagen und fundierte Finanzierungsentscheidungen zu treffen.
Kundensegmentierung im Marketing
Unternehmen verwenden Data Mining, um Kunden in Segmente zu kategorisieren, basierend auf Kaufverhalten und Vorlieben. Diese Segmentierung hilft beim Erstellen maßgeschneiderter Marketingstrategien, die direkt auf die Interessen der jeweiligen Zielgruppen abgestimmt sind.
Gesundheitswesen
Im Gesundheitssektor spielt Data Mining eine Rolle bei der Diagnose von Krankheiten und der Identifikation von Behandlungsmustern durch die Analyse von Patientendaten. Algorithmen können Risiken für bestimmte Erkrankungen identifizieren, sodass frühzeitig Vorsorgemaßnahmen getroffen werden können.
Lieferkettenmanagement
Unternehmen bringen Data Mining in ihren Betrieb ein, um Lieferketten effizienter zu gestalten. Durch die Analyse logistischer Daten lassen sich Engpässe vorhersagen und Strategien entwickeln, um Ressourcen optimal zu verwalten.
Betrugserkennung im E-Commerce
Data Mining wird verwendet, um betrügerische Aktivitäten in Online-Transaktionen zu identifizieren. Durch das Untersuchen von Kaufverhalten können untypische Muster frühzeitig erkannt und Maßnahmen ergriffen werden.
Tipps & Tricks
Data Mining bietet viele Möglichkeiten, jedoch gibt es einige wichtige Hinweise zur optimalen Nutzung:

- Datenqualität sicherstellen: Ohne saubere Daten fehlen die Voraussetzungen für verlässliche Analysen. Bereinigung und Validierung der Daten sind keine optionalen Schritte.
- Algorithmus verstehen: Der gewählte Algorithmus sollte den Daten, dem Ziel und auch der zugrundeliegenden Struktur des Unternehmens gerecht werden.
- Kontinuierliche Überwachung: Regelmäßige Evaluation der Mining-Ergebnisse zur Sicherstellung, dass Modelle stets optimal arbeiten.
- Skalierbarkeit beachten: Besonders bei wachstumsorientierten Projekten muss die gewählte Lösung skalierbar sein.
- Einbeziehung interdisziplinärer Expertise: Datenspezialisten, Business-Analysten und Marketer sollten zusammenarbeiten, um bestmögliche Ergebnisse zu erzielen.
Beziehung zu anderen Fachbegriffen
Data Mining ist eng mit anderen Konzepten der Datenanalyse und Informatik verbunden. Hier sind einige relevante Begriffe:
Big Data
Beziehung: Data Mining ist ein Prozess innerhalb von Big Data, um aus großen Datenmengen verlässliche Muster zu extrahieren.
Zusammenhang: Big Data bezeichnet die riesigen Datenvolumen selbst, während Data Mining die Technik ist, um wertvolle Erkenntnisse aus diesen zu gewinnen.
Data Science
Data Science ist ein interdisziplinäres Feld, das Data Mining, Statistik und Informatik kombiniert, um aus Daten Wissen zu generieren. Data Mining ist ein zentraler Bestandteil von Data Science, da es die Methoden und Techniken bereitstellt, um Muster in Daten zu erkennen.
Business Intelligence (BI)
Business Intelligence bezieht sich auf die Strategien und Technologien, die Unternehmen nutzen, um Daten zu analysieren und geschäftsrelevante Informationen zu gewinnen. Data Mining ist ein wichtiger Bestandteil von BI, da es hilft, verborgene Muster und Trends in Geschäftsdaten zu identifizieren.
Künstliche Intelligenz (KI)
Beziehung: Viele Data Mining-Techniken setzen auf KI-Methoden wie maschinelles Lernen zur Verbesserung der Genauigkeit von Vorhersagen.
Zusammenhang: Im Kontext von KI wird Data Mining oft als Werkzeug genutzt, um die Modelle mit Daten zu füttern und ihre Fähigkeiten zu adaptieren.
Machine Learning
Machine Learning ist ein Teilbereich der Künstlichen Intelligenz, der Algorithmen entwickelt, die aus Daten lernen und Vorhersagen treffen können. Data Mining nutzt Machine Learning-Techniken, um Muster in Daten zu erkennen und daraus Modelle zu entwickeln.
Data Warehousing
Data Warehousing bezieht sich auf die Speicherung und Verwaltung großer Datenmengen in einem zentralen Repository. Data Mining wird häufig auf Daten angewendet, die in Data Warehouses gespeichert sind, um tiefere Einblicke und Analysen zu ermöglichen.
Data Visualization
Data Visualization ist die grafische Darstellung von Daten, um Muster und Trends leichter erkenn bar zu machen. Data Mining-Ergebnisse werden oft durch Visualisierungstechniken präsentiert, um komplexe Datenmuster verständlich zu machen.
Verwechslungsgefahr
Obwohl Data Mining und verwandte Begriffe oft synonym verwendet werden, gibt es wichtige Unterschiede:
Oft wird Data Mining mit Datenanalytik oder einfach nur dem Sammeln von Daten gleichgesetzt. Dies ist jedoch ein Irrtum. Data Mining ist ein spezifischer analytischer Prozess, der weit über das bloße Sammeln oder das generische Analysieren von Daten hinausgeht. Es konzentriert sich auf das Erkennen von Mustern und das Modellieren zukünftiger Szenarien.
Data Mining vs. Datenanalyse
| Kriterium | Data Mining | Datenanalyse |
|---|---|---|
| Ziel | Mustererkennung und Prognosen | Datenmessung und Erkenntnissuche |
| Methoden | Klassifizierung, Clustering, etc. | Statistische und beschreibende Analysen |
| Ergebnisse | Prädiktive Modelle | Berichte, Zusammenfassungen |
| Nutzer | Analysten, Ingenieure | Business-Intelligenz-Profis |
Entwicklungsgeschichte
Große Technologie- und Beratungsunternehmen sind führend in der Data Mining-Entwicklung. IBM bietet die IBM SPSS Modeler Software an, um Data Mining-Prozesse zu erleichtern. SAS Institute ist bekannt für seine umfassenden Analyselösungen. Microsoft und Oracle integrieren Data Mining-Komponenten in ihre Business-Intelligence-Lösungen. Diese Unternehmen investieren fortlaufend in neue Technologien, um den steigenden Ansprüchen an Data Mining-Systeme gerecht zu werden.
- 1960er JahreUrsprung der DatenbankenDatenbanken entstanden und legten den Grundstein für die Datenhaltung, die für Data Mining-Techniken noch unerlässlich ist.
- 1980er JahreErste Data Mining-TechnikenMit dem Aufkommen leistungsfähigerer Computer und mehr Speicherressourcen wurden erste Algorithmen entwickelt, um interessante Muster zu erkennen.
- 1990er JahrePopularisierung durch CRISP-DMDas CRISP-DM-Modell (Cross Industry Standard Process for Data Mining) wurde eingeführt und standardisierte den Data-Mining-Prozess in der Industrie.
- 2000er JahreIntegration von maschinellem LernenMaschinelles Lernen erweiterte die Möglichkeiten des Data Minings erheblich und führte zu verbesserten prädiktiven Modellen.
- 2010er JahreBig Data und Cloud ComputingDie Einführung von Big Data-Technologien im Cloud-Environment führte zu einer völlig neuen Dimension der Datenanalyse und Verwendung von Data Mining.
Zukunft von Data Mining
Data Mining wird voraussichtlich weiterhin eine entscheidende Rolle spielen und durch Entwicklungen in Bereichen wie künstliche Intelligenz, maschinellem Lernen und Quantencomputing noch leistungsfähiger. Die Automatisierung des Data Mining ist ein weiterer Trend, der es selbst Anwendern ohne tiefergehende Fachkenntnisse ermöglichen wird, die Vorteile voll auszuschöpfen. Experten prognostizieren, dass sich die Algorithmen weiterentwickeln und Datenanalytik in Echtzeit ermöglichen werden, was in zahlreichen Bereichen von großem Vorteil ist.
FAQs
Quellen
- Definition: Was ist "Data Mining"? - wirtschaftslexikon
- Data Mining: Algorithmen, Definition, Methoden und Anwendungsbeispiele
- Was ist Data Mining? - bigdata-insider
- Data Mining - mindsquare
- Data Mining - dinext-group

